- Creating a container image
- Running a custom ML model
- Developing your app using Beam’s live reloading workflow
- Pre-loading models and caching them in storage volumes
- Autoscaling and concurrency
Setup your app
You’ll start by adding anendpoint decorator with an Image
Endpointis the wrapper for your inference function.- Inside the
endpointis anImage. TheImagedefines the image your container will run on.
Running a custom ML model
We’ll create a new function to run inference onfacebook/opt-125m via Huggingface Transformers.
Since we’ll deploy this as a REST API, we add an @endpoint decorator above the inference function:
Developing your app on Beam
Beam includes a live-reloading feature that allows you to run your code on the same environment you’ll be running in production.By default, Beam will sync all the files in your working directory to the
remote container. This allows you to use the files you have locally while
developing. If you want to prevent some files from getting uploaded, you can
create a
.beamignore.beam serve app.py:predict. This will:
- Spin up a container
- Run it on a GPU
- Print a cURL request to invoke the API
- Stream the logs to your shell
beam serve, you’ll notice the server reloading with your code changes.
You’ll use this workflow anytime you’re developing an app on Beam. Trust us — it makes the development process uniquely fast and painless.
Performance Optimizations
If you called the API via the cURL command, you’ll notice that your model was downloaded each time you invoked the API. In order to improve performance, we’ll setup a function to pre-load your models and store them on disk between API calls.Pre-loading
Beam includes anon_start method, which you can pass to your function decorators. on_start is run exactly once when the container first starts:
The value of the on_start function can be retrieved from context.on_start_value:
Cache in a storage volume
Theon_start method us from having to download the model multiple times, but we can avoid downloading the model entirely by caching it in a Storage Volume:
Beam allows you to create highly-available storage volumes that can be used across tasks. You might use volumes for things like storing model weights or large datasets.
cache_dir argument in transformers:
Configure Autoscaling (Optional)
You can control your autoscaling behavior withQueueDepthAutoscaler.
QueueDepthAutoscaler takes two parameters:
max_containerstasks_per_container
Deployment
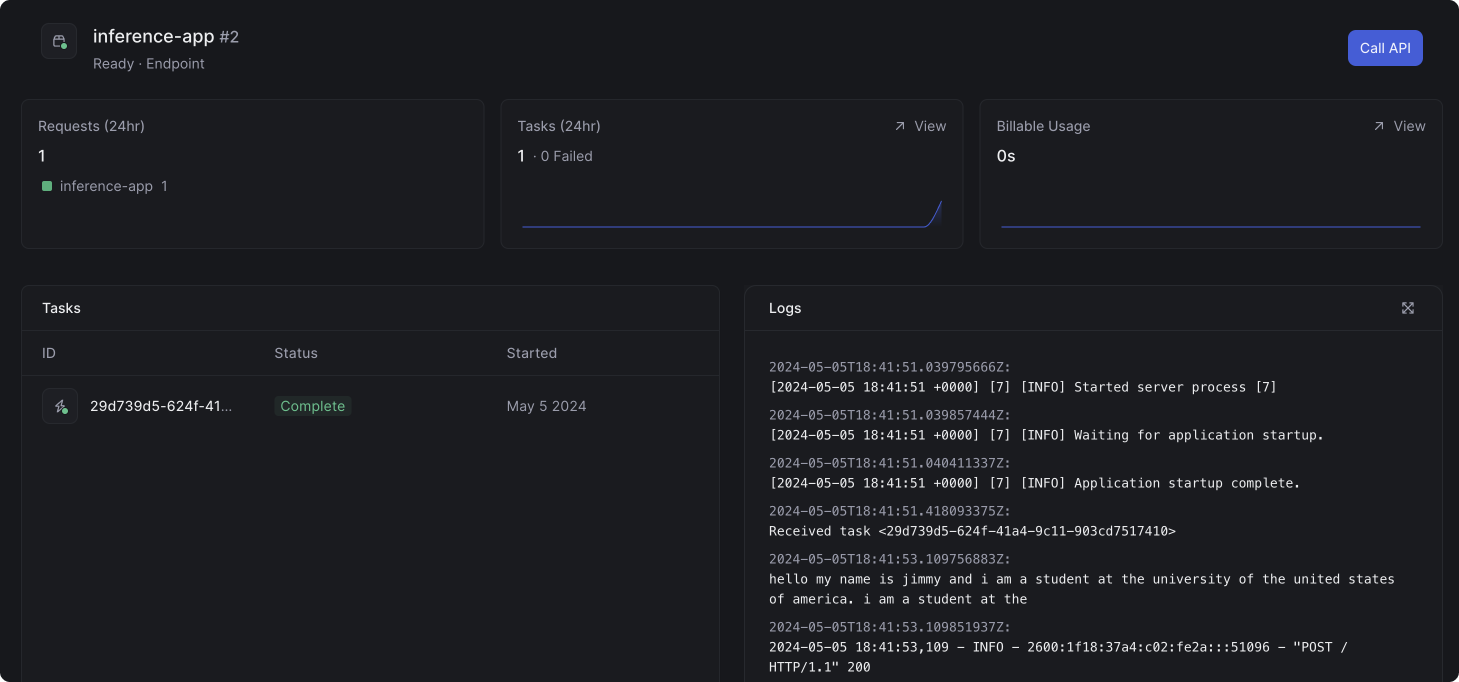
With these performance optimizations in place, it’s time to deploy your API to create a persistent endpoint. In your shell, run this command to deploy your app:Monitoring Logs and Task Status
In the dashboard, you can view the status of the task and the logs from the container: