Cold Start Optimizations
Cache Models in Volumes
To avoid downloading your models from the internet on each request, you can cache them in Beam’s Volumes. In the example below, the models are saved to the Volume by passing thecache_dir argument in the Huggingface Transformers method:
cache_dir argument to the underlying models using the model_kwargs argument of the pipeline:
Load Models Using on_start
In addition to using a Volume, it’s best-practice to ensure models are only loaded once when the container first starts. Beam lets you define an on_start function that will run exactly once when the container first starts:
This example combines the on_start functionality with the Volume caching:
Enable Checkpoint Restore (New)
This allows you to specify acheckpoint_enabled flag on your decorator, which will capture a memory snapshot of the running container after on_start completes. This means that you can load a model onto a GPU, run some setup logic, and when the app cold starts, it will start right from that point.
- RTX4090
- H100
- A10G
Notes
- If checkpoint fails, please forward us any errors that appear in logs. It’s likely the reason for failure is a missing volume — to resolve that you need to ensure the cache path is set properly for the model.
- If checkpoint fails, the deployment will revert to standard cold boots. To try checkpointing again, you will need to redeploy.
Checkpoints can take up to 3 minutes to capture, and 5 minutes to distribute
among our servers. To properly benchmark the cold start improvement, you need
to call the app after it has been spun down for a few minutes. Otherwise it
may block as the checkpoint is syncing.
Measuring Cold Start
We’ve made it easier to optimize your cold starts by adding a cold start profile to each task. You can view the cold start profile of a task by clicking on any task in the tasks table.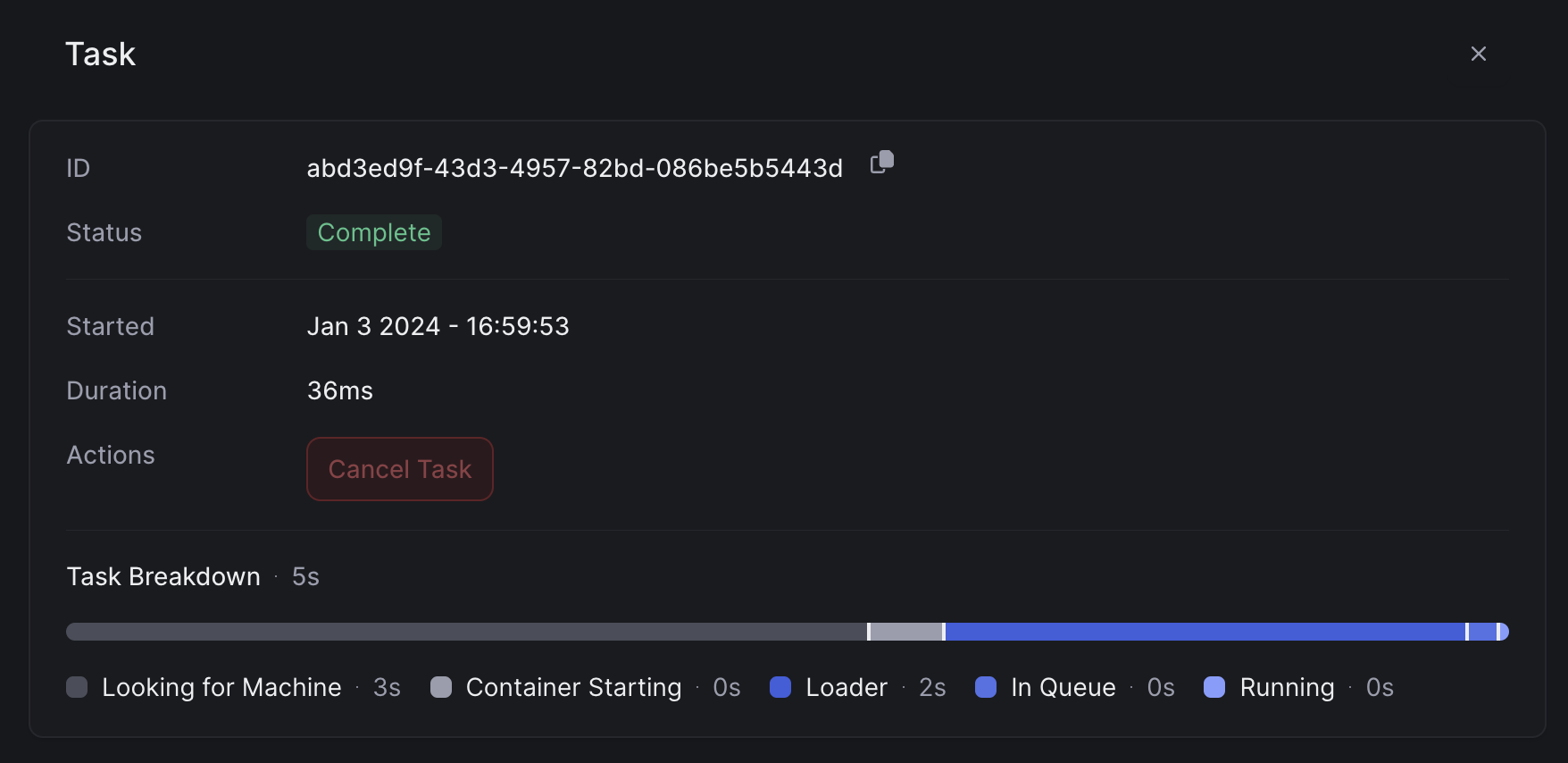
on_start function, and running the task itself.
Here’s a breakdown of a serverless cold start:
- Container Start Time. This is typically under 1s.
- Image Load Time. Pulling your container image from our image cache. This varies based on the size of your model and the dependencies you’ve added.
- Application Start Time. Running your code. This is the time running your
on_start, and loading it on the GPU.