View the Code
See the code for this example on Github.
Fine-Tuning
In this example, we are using Low-Rank Adaption (LoRA) to fine-tune the Gemma language model using the Open Assistant dataset. The goal is to use this dataset to improve Gemma’s ability to engage in helpful conversations, making it more suitable for assistant-like apps.LoRA
You can read more about LoRA here. However, let’s briefly discuss what exactly it does and why we chose to use it here. At a high level, LoRA introduces a new small set of weights to the model that we will be training. By limiting our training to these additional weights, we can fine-tune the model much quicker. Additionally, since we are not touching the original weights, the model’s initial knowledge base should intact.Initial Setup
In this example, we are using an H100 GPU. We are using mixed precision (FP16) to optimize for speed and memory usage. In this example, we are only training for one epoch. In practice, you can probably train longer and continue to see improved results. No surprise here, but we are getting our compute via Beam. We are using thefunction decorator so that we can run our fine-tuning application as if it were on our local machine.
Mounting Storage Volumes
We’re using Beam’s persistent storage volumes to store model weights and training data. This allows us to download the necessary files directly to the volume, streamlining the setup process. Here’s a simple script to handle the downloads:Start Training
We can start our training by runningpython finetune.py. After beginning training, you should see something like the following in your terminal:
Inference
Ininference.py, we are loading up our model with the additional fine-tuned weights and setting up an endpoint to send it requests.
Here, we make use of the Beam’s on_start functionality so that we only load the model when the container starts instead of every time we receive a request. Let’s explore the endpoint decorator below.
Choosing a GPU For Inference
Now that we’ve trained the model, we can run it on a machine with a weaker GPU. Training requires more memory than inference because it must store gradients and optimizer states for all parameters, in addition to activations, whereas inference only needs to maintain the current layer’s activations during a forward pass. Be sure to keep this in mind as you work on your own applications. You can use the Beam dashboard to get a sense of GPU utilization in real-time. With this information, you can make a more informed choice about how much compute you require. For this example, we use a T4 GPU. It has 16GB of VRAM and is a good choice for inference with a model this small.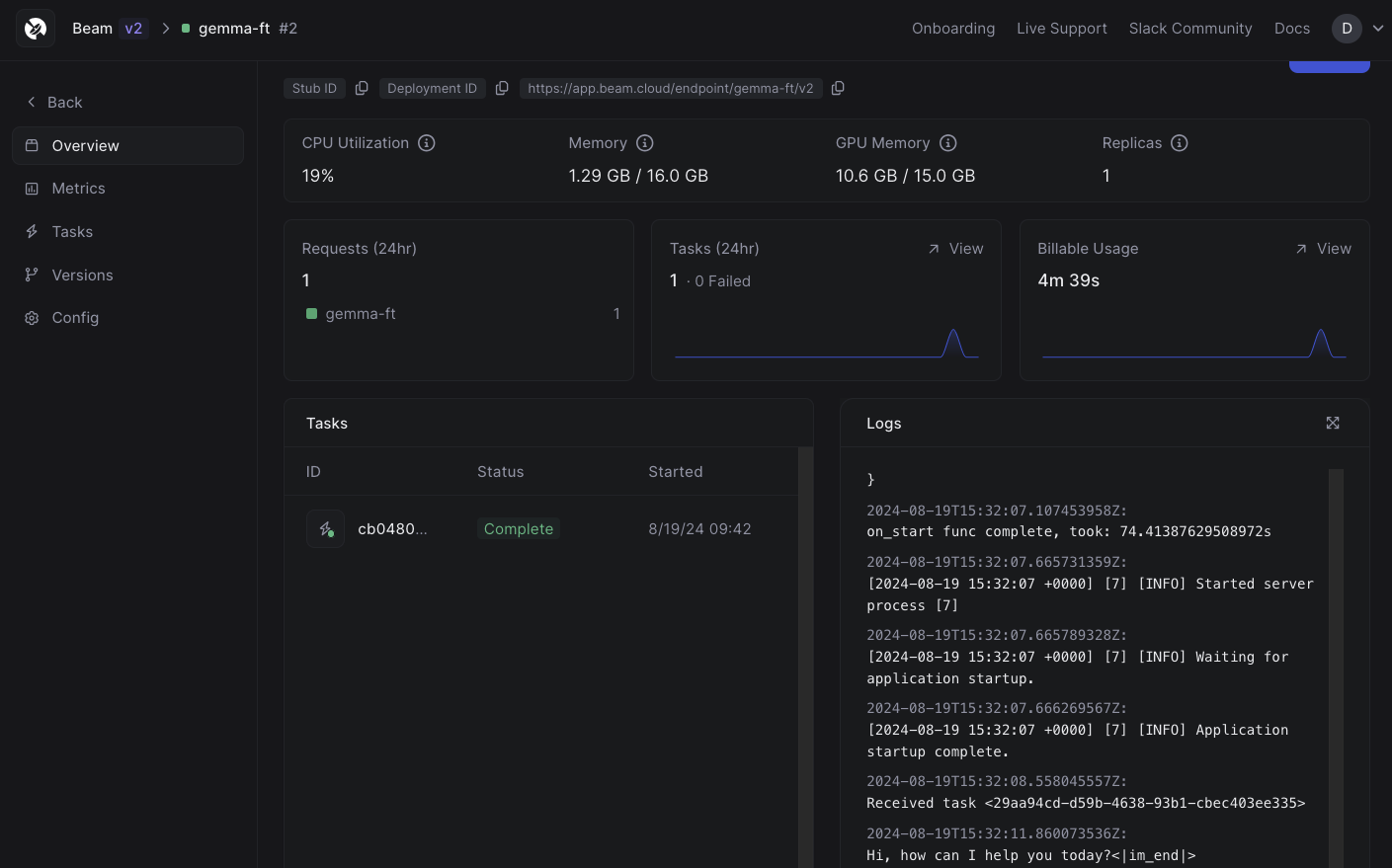
Monitoring compute usage in real-time in the dashboard
Using Signals to Reload Model Weights Automatically
We use aSignal abstraction to fire an event to the inference app when the model has finished training.
This allows us to communicate between apps on Beam. In this example, we have it setup to re-run our on-start method when a signal is received. This way, if we re-train our model, we can load the newest weights without restarting the container.
Deploying The Endpoint
Let’s deploy our endpoint! We can do this with thebeam CLI.
-d '{"prompt": "hi"}. The response we get back will be in the following format:
<|im_end|>. You could strip this token in the endpoint logic if you would like, but it is worth keeping around if you will be appending this response to a longer running conversation.