View the Code
See the full code for this example on GitHub.
Setup
Environment Configuration
We define a sharedImage configuration for both fine-tuning and inference, ensuring consistency. The image includes necessary dependencies and installs Unsloth from its GitHub repository.
To use Weights & Biases (wandb) for tracking, you’ll need your API key. You
can find it in your wandb dashboard under the
“API keys” section. Copy the key and replace
YOUR_WANDB_KEY in the wandb login command.finetune.py
Fine-Tuning
The fine-tuning script (finetune.py) uses Unsloth to adapt the model to the Alpaca-cleaned dataset while tracking metrics with Weights & Biases.
Running Fine-Tuning
Execute the script:Training Performance Metrics
We tracked our fine-tuning process using Weights & Biases, which provided detailed metrics on training progress. The dashboard showed that the training loss started at approximately 1.85 and, despite significant fluctuations, exhibited a general downward trend, ending at around 0.95 by step 60. This suggests that the model was learning patterns from the Alpaca-cleaned dataset over the 60 training steps.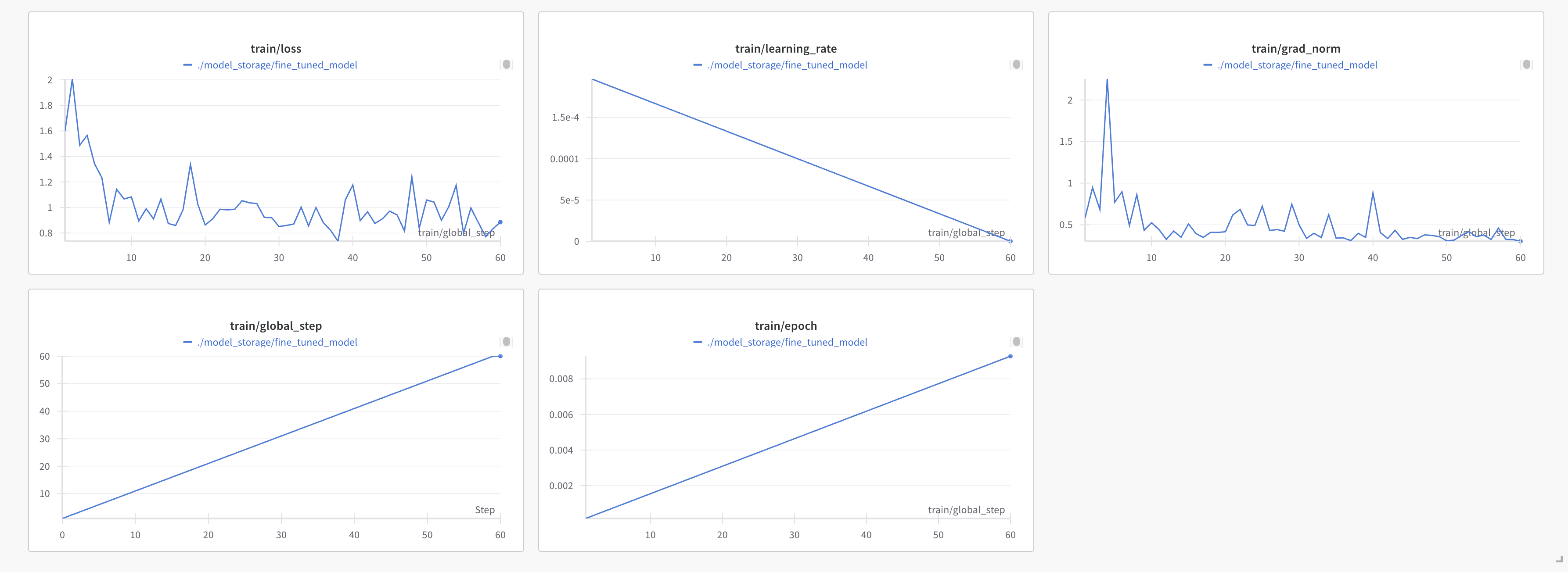
Evaluation
To understand the impact of fine-tuning the Meta Llama 3.1 8B model with Unsloth on the Alpaca-cleaned dataset, we evaluated both the base model and the fine-tuned model on two widely used benchmarks: HellaSwag (a commonsense reasoning task) and MMLU (Massive Multitask Language Understanding, covering a broad range of subjects). The results highlight the fine-tuned model’s improvements over the base model, demonstrating the effectiveness of our fine-tuning process.Overall Performance
The table below summarizes the overall performance on HellaSwag and MMLU. The fine-tuned model shows modest but consistent gains across both benchmarks.- HellaSwag: The fine-tuned model improves accuracy (acc) by 1.28% and normalized accuracy (acc_norm) by 0.82%, indicating better commonsense reasoning capabilities.
- MMLU: An overall improvement of 0.91% suggests the model has enhanced its general knowledge and reasoning across diverse topics.
Analysis
The fine-tuned model demonstrates consistent improvements over the base model, particularly in tasks requiring logical reasoning, ethical judgment, and commonsense understanding. These gains align with the Alpaca-cleaned dataset’s focus on instruction-following and coherent responses.Inference
Inference Script
The inference script (inference.py) loads the fine-tuned model and exposes an endpoint for generating responses.